
OpenAI深夜发布“王炸”功能!文字直接生成视频,网友惊呼:颠覆电影行业(视频/组图)
2月16日凌晨,OpenAI再次扔出一枚深水炸弹,发布了首个文生视频模型Sora。
据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。
目前官网上已经更新了48个视频demo,在这些demo中,Sora不仅能准确呈现细节,还能理解物体在物理世界中的存在,并生成具有丰富情感的角色。
该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
例如一个Prompt(大语言模型中的提示词)的描述是:在东京街头,一位时髦的女士穿梭在充满温暖霓虹灯光和动感城市标志的街道上。
在Sora生成的视频里,女士身着黑色皮衣、红色裙子在霓虹街头行走,不仅主体连贯稳定,还有多镜头,包括从大街景慢慢切入到对女士的脸部表情的特写,以及潮湿的街道地面反射霓虹灯的光影效果。

电影预告片讲述了30岁宇航员戴着红色羊毛针织摩托车头盔的冒险经历,蓝天、盐漠,电影风格,35毫米胶片拍摄,色彩鲜艳。
AI想象中的龙年春节,红旗招展人山人海。有紧跟舞龙队伍擡头好奇观望的儿童,还有不少人掏出手机边跟边拍,海量人物角色各有各的行为。

竖屏超近景视角下,这只蜥蜴细节拉满:

网友直呼game over,工作要丢了:

甚至有人已经开始“悼念”一整个行业:
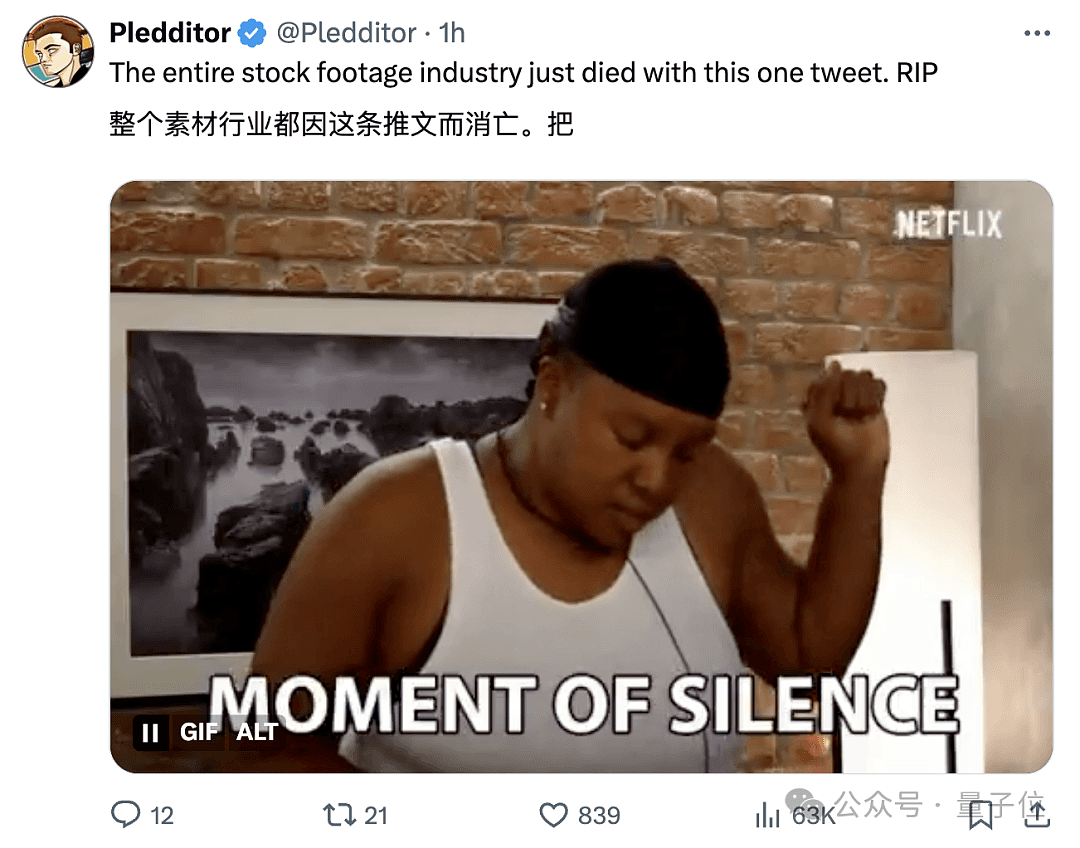
还有网友表示,电影业要彻底颠覆了。





一位YouTube博主Paddy Galloway发表了对Sora的感想,他表示内容创作行业已经永远的改变了,并且毫不夸张。“我进入YouTube世界已经15年时间,但OpenAI刚刚的展示让我无言…动画师/3D艺术家们有麻烦了,素材网站将变得无关紧要,任何人都可以无壁垒获得难以置信的产品,内容背后的‘想法’和故事将变得更加重要。”
对于Sora当前存在的弱点,OpenAI也不避讳,指出它可能难以准确模拟复杂场景的物理原理,并且可能无法理解因果关系。
例如“五只灰狼幼崽在一条偏僻的碎石路上互相嬉戏、追逐”,狼的数量会变化,一些凭空出现或消失。

该模型还可能混淆提示的空间细节,例如混淆左右,并且可能难以精确描述随着时间推移发生的事件,例如遵循特定的相机轨迹。
如提示词“篮球穿过篮筐然后爆炸”中,篮球没有正确被篮筐阻挡。

OpenAI表示,他们正在教AI理解和模拟运动中的物理世界,目标是训练模型来帮助人们解决需要现实世界交互的问题。
随后OpenAI解释了Sora的工作原理,Sora是一个扩散模型,它从类似于静态噪声的视频开始,通过多个步骤逐渐去除噪声,视频也从最初的随机像素转化为清晰的图像场景。Sora使用了Transformer架构,有极强的扩展性。
视频和图像是被称为“补丁”的较小数据单位集合,每个“补丁”都类似于GPT中的一个标记(Token),通过统一的数据表达方式,可以在更广泛的视觉数据上训练和扩散变化,包括不同的时间、分辨率和纵横比。
Sora是基于过去对DALL·E和GPT的研究基础构建,利用DALL·E 3的重述提示词技术,为视觉模型训练数据生成高描述性的标注,因此模型能更好的遵循文本指令。
如今,Sora正面向部分成员开放,以评估关键领域的潜在危害或风险。同时,OpenAI也邀请了一批视觉艺术家、设计师和电影制作人加入,期望获得宝贵反馈,以推动模型进步,更好地助力创意工作者。OpenAI提前分享研究进展,旨在与OpenAI以外的人士合作并获取反馈,让公众了解即将到来的AI技术新篇章。









 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


